Abstract
Visual world models have shown great potential in learning complex system dynamics. Recent advancements leverage these models as transition functions within Model Predictive Control (MPC) frameworks to solve various control tasks. When applied to robotics, however, they are limited to single-stage tasks such as reaching or grasping, and struggle with multi-stage ones that demand complex sequential planning. In this work, we introduce WorldDP, a world model framework designed for multi-stage robotic manipulation. Our hierarchical approach utilizes a high-level world model as a transition function to optimize for feasible subgoals during runtime, which are subsequently reached by a low-level Diffusion Policy. To further aid in learning dynamics and planning, we incorporate object-centric representations that decouple environmental entities and enable us to plan sequentially with respect to each. valuated across several robotics benchmarks, WorldDP consistently outperforms existing baselines, validating that coupling the world model’s physically groundedplanning with diffusion policy’s efficient execution yields superior multi-stage performance.
Method
Object-Centric Encoder
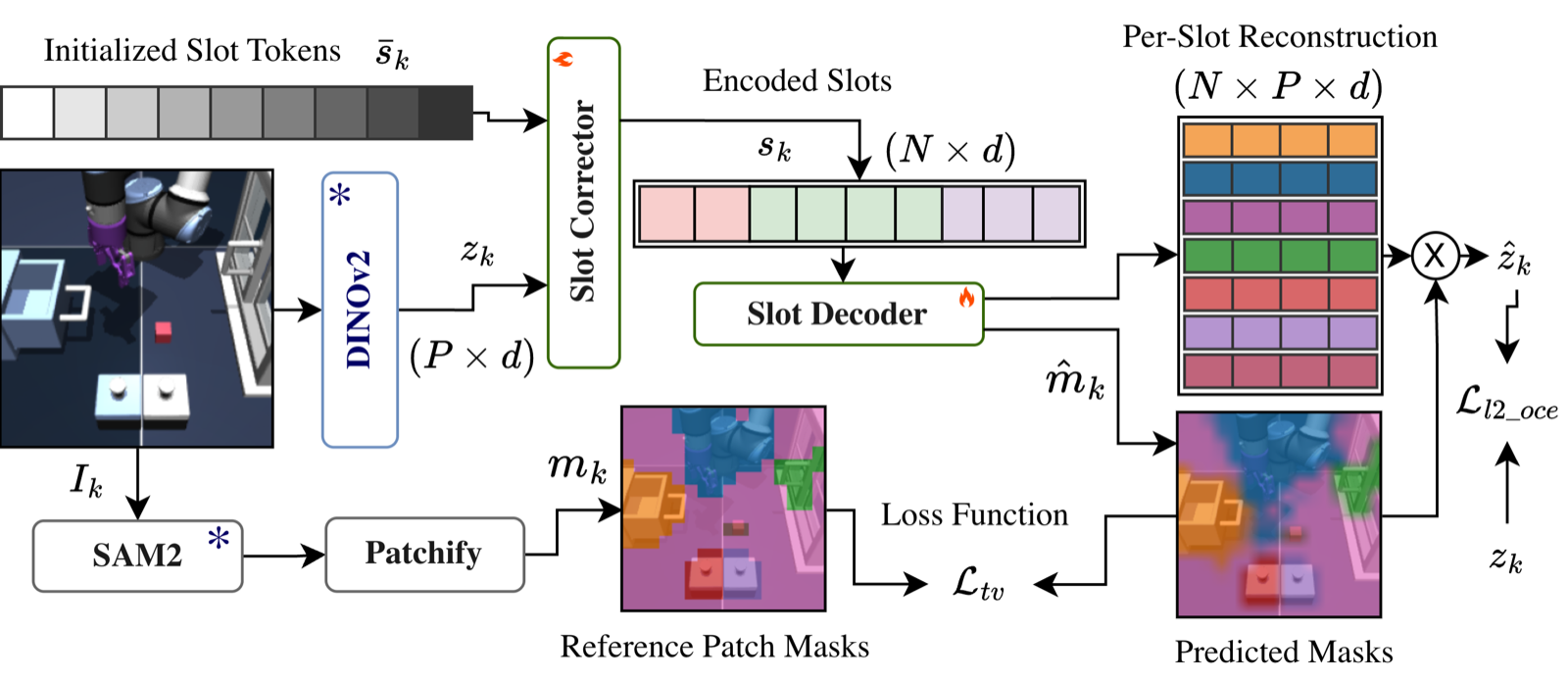
We adopt an object-centric state representation that decouples environment entities (the agent, objects, and background) learned on top of frozen DINOv2 patch features with privileged SAM2 guidance during training. This facilitates better attention to relevant entities and enables individual planning for each item during MPC.
Conditional Diffusion Transformer Dynamics Model
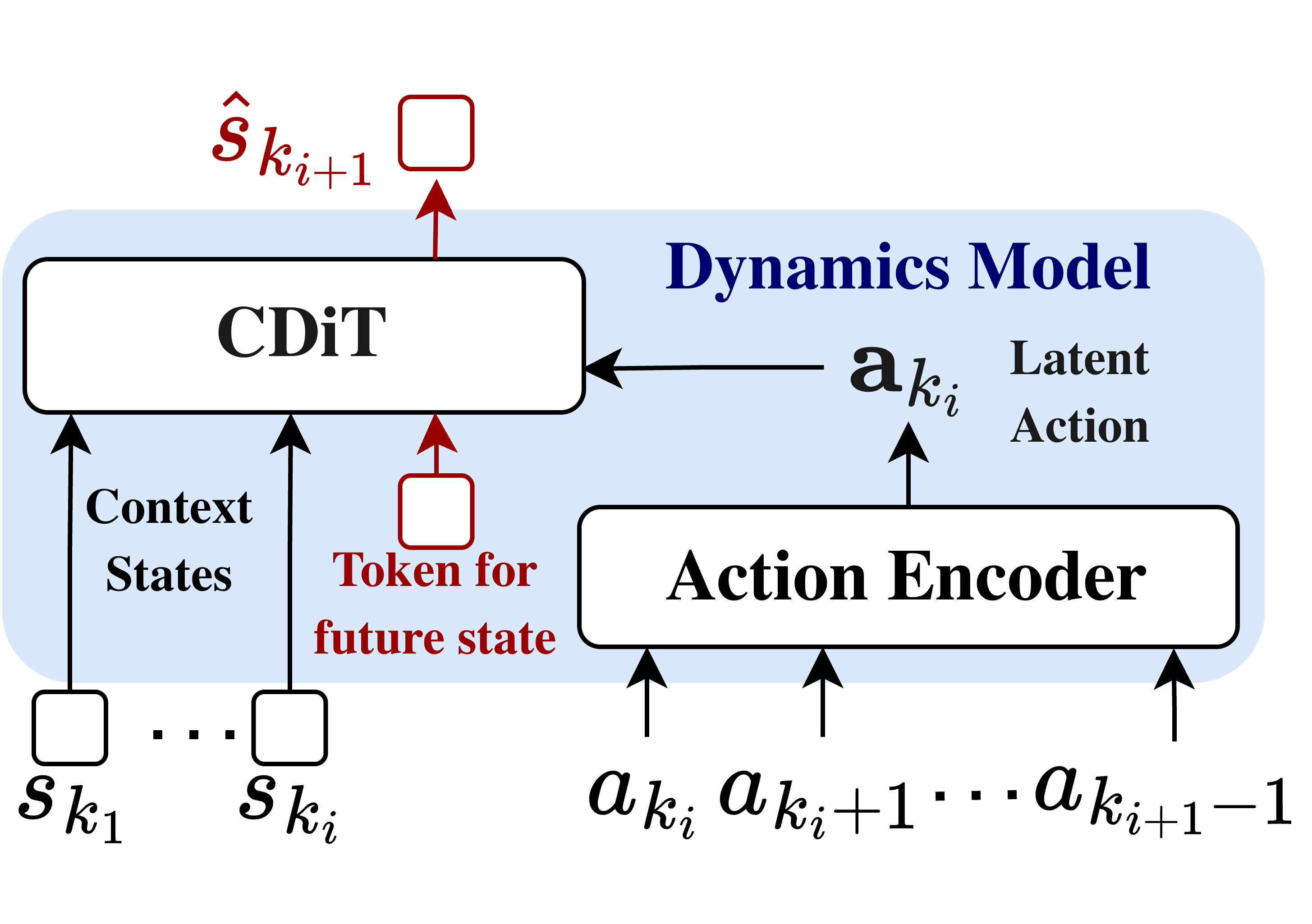
A Conditional Diffusion Transformer (CDiT) takes the object-centric states and a compressed latent action embedding to predict subsequent entity states at a future timestep. The action sequence is compressed into a latent action embedding via a transformer-based action encoder, which conditions the CDiT through Adaptive Layer Normalization (AdaLN) layers. During planning the model operates autoregressively, iteratively feeding back predicted states and action chunks to roll out future states.
Hierarchical Task Execution
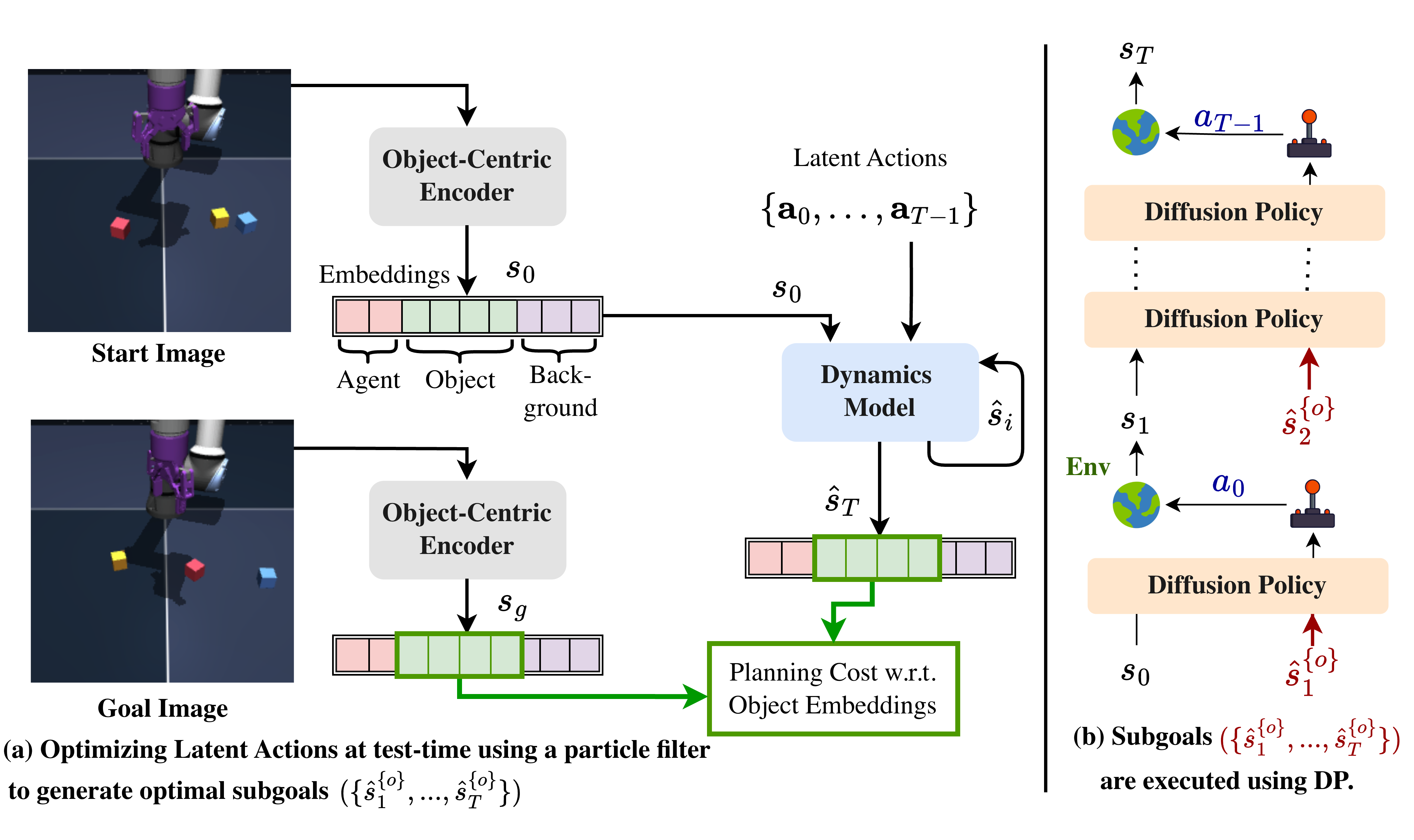
Pseudo-code of WorldDP's hierarchical planning. Given the current observation and target goal, a particle filter optimizes latent action sequences through the world model to generate optimal subgoals. These subgoals are tracked and executed via the low-level diffusion policy.
def WorldDPPlanning(obs, goal, action_means, **kwargs):
"""
obs: environment observation
goal: goal image
action_means: initialized means for the particle filter
kwargs: contains parameters like total_iter, lambda_plan
"""
# 1. World Model Subgoal Planning via Particle Filtering
for iter_idx in range(total_iters):
# A. Generate action particles around the current means
action_particles = sample_around_mean(action_means, sigma, total_samples)
# B. Evaluate particles through autoregressive rollouts
total_costs = []
for action in action_particles:
pred_states, object_cost, contact_cost = get_costs(obs, action, goal)
total_costs.append(object_cost + lambda_plan*contact_cost)
# C. Select top-M candidates as means for next iteration
top_m_idx = top_m_indices(total_costs, top_m)
action_means = [action_particles[i] for i in top_m_idx]
# 2. Extract optimal subgoal sequence from highest-ranking particle
optimal_subgoals, _, _ = get_costs(obs, action_means[0], goal)
# 3. Goal-Conditioned Diffusion Policy to reach subgoals
curr_obs = env.get_info()
for subgoal in optimal_subgoals:
low_level_actions = diff_policy(curr_obs, subgoal)
curr_obs, is_success = env.step(low_level_actions)
return is_success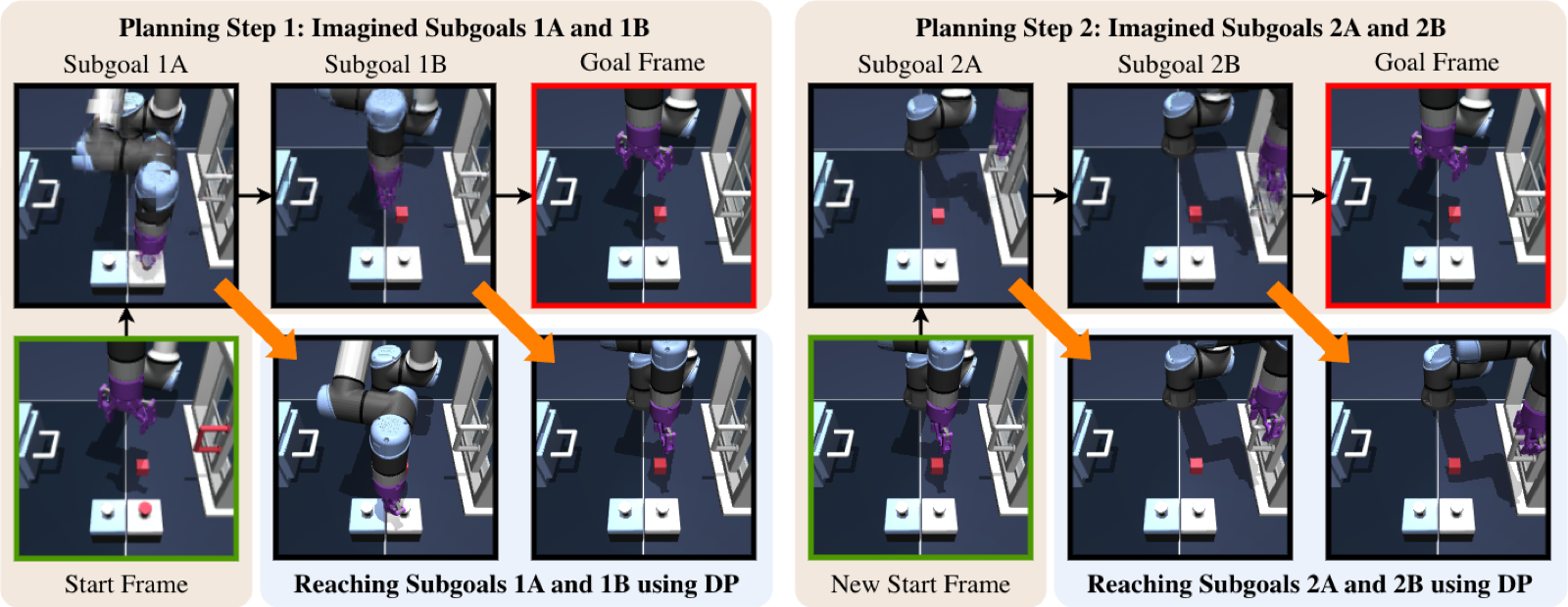
Task execution is formulated as a hierarchical two-tier MPC framework. The upper tier uses the world model to plan high-level subgoals from a target goal image, optimizing latent action sequences with a Particle Filter against an object-centric cost augmented by a contact-prediction term. The lower tier employs a goal-conditioned Diffusion Policy to realize these subgoals — robust for short-horizon control, fast to execute, and able to compensate for suboptimal subgoals.
Robotic Tasks
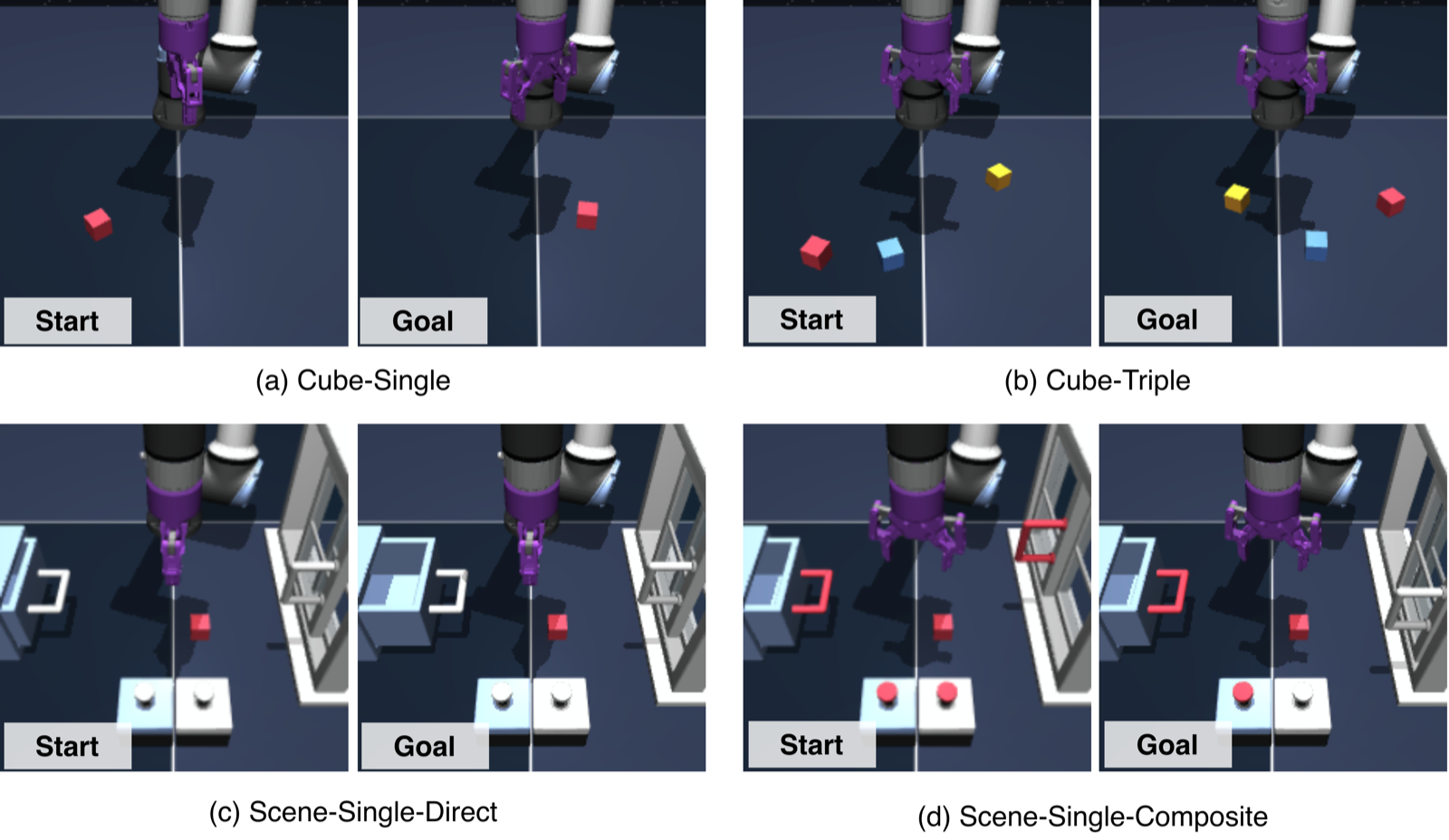
- Cube-Single: A UR5e arm and a single red cube; manipulate the cube from its initial position to a target location specified by a goal image.
- Cube-Triple: Three distinct cubes (red, blue, yellow); sequentially rearrange them from their initial positions to match a randomly sampled goal configuration.
- Scene-Single-Direct: A scene with a drawer, sliding window, cube, and two push buttons; the goal image differs from the initial state by exactly one object modification.
- Scene-Single-Composite: The same layout, but the agent must first interact with the appropriate button to unlock the drawer or window before executing the target manipulation.
Task Execution
WorldDP decomposes each multi-stage task into reachable subgoals executed by the low-level diffusion policy. Each clip shows the Start state, Ours (WorldDP execution), and the target Goal state.
World Model Rollouts
Open-Loop Trajectory Rollouts. Given an initial state and an action sequence, the world model generates a predicted trajectory. Comparing it with the ground truth demonstrates the model's accurate simulation capabilities. Latent states are decoded into images for visualization.
Cube-Single


Cube-Triple


Scene-Single


Results
Success rate (%) across multi-stage manipulation tasks. WorldDP consistently outperforms existing world-model and diffusion-based baselines. Best results per column are highlighted.
Cube-Triple & Scene-Single-Composite
For Cube-Triple, 1/2/3 Cubes refer to at least 1, 2, and all 3 cube successes.
| Methods | Cube-Triple | Scene-Single-Composite | |||
|---|---|---|---|---|---|
| 1-Cube | 2-Cubes | 3-Cubes | Button Press | Full Task | |
| DINO-WM | 62 | 10 | 0 | 8 | 0 |
| LeWM | 74 | 8 | 0 | 4 | 0 |
| HECRL* | 78 | 34 | 12 | 60 | 18 |
| DP40 | 42 | 12 | 0 | 64 | 0 |
| DP100 | 90 | 32 | 4 | 78 | 14 |
| WorldDP (Ours) | 100 | 72 | 30 | 60 | 20 |
Cube-Single & Scene-Single-Direct
| Methods | Cube-Single | Scene-Single-Direct | Both Task Average |
|||
|---|---|---|---|---|---|---|
| Button | Drawer | Window | Average | |||
| DINO-WM | 0 | 25 | 23.53 | 5.88 | 18 | 9 |
| LeWM | 0 | 12.5 | 11.76 | 23.53 | 16 | 8 |
| HECRL* | 98 | 31.25 | 52.94 | 5.88 | 30 | 63 |
| DP40 | 0 | 87.5 | 35.29 | 11.76 | 44 | 32 |
| DP100 | 98 | 50 | 23.53 | 5.88 | 26 | 63 |
| WorldDP (Ours) | 72 | 81.25 | 76.47 | 64.71 | 74 | 74.5 |
Object-Centric Encoding
Object-Centric Encoding Visualization. Left: image; Right: predicted masks from the OCE embeddings. Because the OCE operates on patch-level DINOv2 features, masks are patch-level, yielding coarser, block-like boundaries that encapsulate each object of interest.


